
'No more loops' – benchmarking the new Java 8 Stream API
There was a link to an interesting blog post recently posted on proggit. The article, titled ‘Java 8: No more loops’, advises eschewing imperative constructs like loops and manipulating collections directly, in favor of functional programming solutions enabled by things like lambda expressions, streams and method references. It illustrates its point by implementing four methods dealing with a simple Article type in two ways: the “old” way by using loops and the “new” way by using the new Java 8 features. In the comments, a lot of people were wondering how does the stream solutions compare in terms of performance to the imperative code. I was kind of wondering that myself, and couldn’t recall seeing any benchmark that would directly address the effectiveness of streams. So I wrote one myself.
For convenience, here’s the original code (I copied it unchanged):
public class Article {
private final String title;
private final String author;
private final List<String> tags;
public Article(String title, String author, List<String> tags) {
this.title = title;
this.author = author;
this.tags = tags;
}
public String getTitle() {
return title;
}
public String getAuthor() {
return author;
}
public List<String> getTags() {
return tags;
}
}
public class ArticleOps {
private final List<Article> articles;
public ArticleOps(List<Article> articles) {
this.articles = articles;
}
public Article getFirstJavaArticle_loop() {
for (Article article : articles) {
if (article.getTags().contains("Java")) {
return article;
}
}
return null;
}
public Optional<Article> getFirstJavaArticle_stream() {
return articles.stream()
.filter(article -> article.getTags().contains("Java"))
.findFirst();
}
public List<Article> getAllJavaArticles_loop() {
List<Article> result = new ArrayList<>();
for (Article article : articles) {
if (article.getTags().contains("Java")) {
result.add(article);
}
}
return result;
}
public List<Article> getAllJavaArticles_stream() {
return articles.stream()
.filter(article -> article.getTags().contains("Java"))
.collect(Collectors.toList());
}
public Map<String, List<Article>> groupByAuthor_loop() {
Map<String, List<Article>> result = new HashMap<>();
for (Article article : articles) {
if (result.containsKey(article.getAuthor())) {
result.get(article.getAuthor()).add(article);
} else {
ArrayList<Article> articles = new ArrayList<>();
articles.add(article);
result.put(article.getAuthor(), articles);
}
}
return result;
}
public Map<String, List<Article>> groupByAuthor_stream() {
return articles.stream()
.collect(Collectors.groupingBy(Article::getAuthor));
}
public Set<String> getDistinctTags_loop() {
Set<String> result = new HashSet<>();
for (Article article : articles) {
result.addAll(article.getTags());
}
return result;
}
public Set<String> getDistinctTags_stream() {
return articles.stream()
.flatMap(article -> article.getTags().stream())
.collect(Collectors.toSet());
}
}
The code of the benchmark is available on GitHub. It uses the JMH library. Here are the results on my machine, operating on 10,000 randomly generated Article objects (this is in microseconds per method invocation, so lower is better):
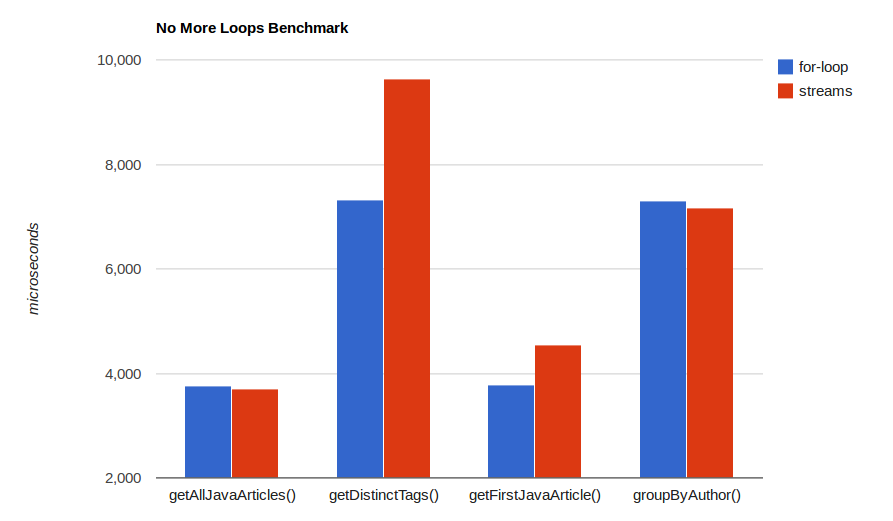
As you can see, the results are very close. getAllJavaArticles and groupByAuthor are practically undistinguishably close. Both getFirstJavaArticle and getDistinctTags are faster with for loops – the first one by about 16%, the second around 24%. I should add that I generated the test data purposefully in a way in which there was no Java article, so that both versions of getAllJavaArticles and getFirstJavaArticle had to do their “worst case” (traverse the entire collection).
I think the results are clear – the performance of the Streams API is excellent, in some cases better than a hand-written loop, and not noticably worse in others. Therefore, performance should not be a consideration when choosing between the two styles – rather, readability and ease of maintenance should be the deciding factors.
I encourage you to play with the benchmark yourself. Did your results match mine? Let me know in the comments! Also, this was my first experience writing Java benchmarks – if you have anything to say about that part, I encourage you to give me some feedback, either here or on GitHub.